

The best way to search for duplicates depends on the type of duplicates and what should happen to the duplicates found:
- Search intelligently for duplicates and duplicate addresses (deduplication) with DataQualityTools:
If it is to be particularly comfortable or if the duplicates to be found are duplicates that are difficult to find, then you can hardly do without a software specially designed for this problem. DataQualityTools find duplicates even if they differ from each other to a certain extent. This is especially helpful for address lists, where spelling mistakes and spelling variations are the rule rather than the exception. Further information ... - Suppress duplicates with the 'distinct' command:
If you are looking for easy to find duplicate values, such as duplicate customer or article numbers, and want to suppress them in the result of a database query, you can use the SQL command 'distinct'. Further information ... - Hide duplicates with the 'group by' command:
If you are looking for easy to find duplicate values, such as duplicate customer or article numbers, and want to hide them in the result of a database query, you can use the SQL command 'group by'. Further information ... - Search for duplicates with the 'select' command:
If you are looking for easy to find duplicate values, such as duplicate customer or article numbers, and if the hits are to be deleted directly from the database or if data records are to be supplemented and completed on the basis of the result, the SQL command 'select' can be used. Further information ...
1. Search intelligently for duplicates and duplicate addresses (deduplication) with DataQualityTools in Access
DataQualityTools find duplicates even if they differ from each other to a certain extent. This is especially helpful for address lists, where spelling mistakes and spelling variations are the rule rather than the exception. Proceed as follows:
- If you have not already done so, download DataQualityTools free of charge here. Install the program and request a trial activation. Then you can work with the program for one whole week without any restrictions.
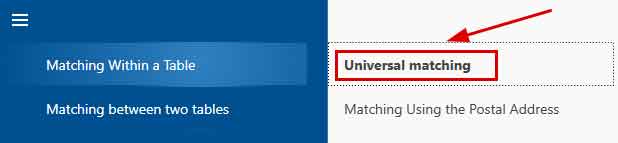
- The functions we need can be found in the menu of the 'Matching within a table' block. Let’s choose 'Universal Matching'.
- After starting this function, the project management appears. Here, you create a new project with a project name of your choice and then click on the 'Next' button.
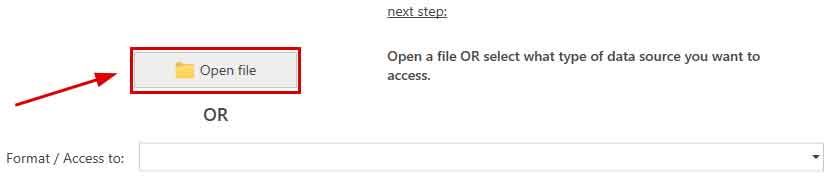
- In the next step, we start by opening the Access file with the data to be processed by clicking on the 'Open file' button.
After that, we enter the name of the database server. After clicking on the 'Connect to server' button, the access data have to be entered. Finally, the desired database containing the table can be selected in the corresponding selection lists. - Then you have to tell the program which of the columns from the table you want to compare:
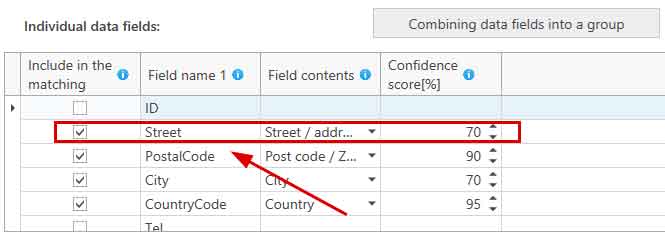
In this example, the column 'Street' is to be compared with. This contains the street name, which is why 'Street' was selected from the selection list for the field content. And 50% has been chosen as the threshold for the configence score. The street name must therefore be at least 50% the same, so that the data record in question appears as a hit in the results.
If required, individual columns can also be combined to form a group:
The contents of the columns are then summarised in the group before the comparison and are thus compared together. - With a click on the button 'Next', we get to a dialogue with further options. But we don't need them here.
- A click on the 'Next' button starts the matching. In no time at all, a summary of the results is displayed. If the program has found duplicates in the processed table, a click on the 'Show / edit results' button leads to an overview of the result:

Here, the results of the comparison is presented in table form. Those records that should be deleted are marked with a red X, which can be removed if necessary. - Finally, the result has to be processed further. For example, we could mark the records marked for deletion directly in the source table in Access with a deletion flag. To do this, we select the appropriate function by first clicking on 'Flagging functions':

And then click on 'Flagging in the Source Table':
Then you have to specify what the deletion flag should look like and in which data field the marking should be written: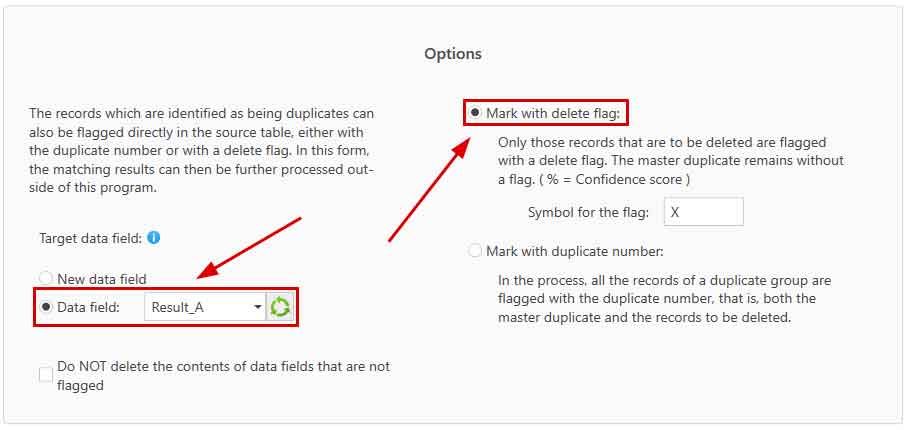
2. Suppress duplicates with the 'distinct' command in Access
Suppose that from the table with the ordered articles, all article numbers which an individual customer has ordered are to be determined, whereby in the result each article number may occur with a customer only once. The database query for this could look like this:
SELECT DISTINCT customer_id, article_no
FROM customer_articles
ORDER BY customer_no, article_no
The 'distinct' refers to all columns specified at 'select'. As a result, each article number is listed here with each customer number, but each combination of article number and customer number is listed only once. In combination with the 'into' command you can also remove duplicate records from a table:
SELECT DISTINCT customer_id, article_no
INTO table_new
FROM customer_articles
ORDER BY customer_no, article_no
The data cleansed of duplicates is written to a new table.
3. Hide duplicates with the 'group by' command in Access
Suppose that the article numbers are to be determined from the table with the ordered articles, whereby in the result each article number may occur only once. The database query for this could look like this:
SELECT article_no, COUNT(*), SUM(revenue)
FROM invoice_articles
GROUP BY article_no
ORDER BY COUNT(*), article_no
In addition to the article number, this query returns the number of records that contain this article number and the sum of the sales from these records.
4. Search for duplicates with the 'select' command in Access
Exact duplicates, i.e. duplicate records that are completely identical except for capitalisation, are relatively easy to find using SQL queries. Although the query assistant in Access includes an option to create a query for a duplicates search, the results only list the duplicate terms and the number of times they occur in the table. Unfortunately, the duplicates that were found cannot be deleted this way. For this reason, there is no way to avoid making an individual SQL query for this purpose in Access.
The easiest way is to start by creating a new query scheme and then switch over to the direct entry of SQL commands using the menu item ‘SQL view’ from the context menu or using the small 'SQL‘ symbol at the very bottom right edge of the window. Here, just like with other database servers, you can enter SQL commands. The entered SQL command can be executed using the ‘Execute’ button. The small 'SQL‘ symbol at the very bottom right edge of the window takes you back to the corresponding SQL query.
For the following query, for example, Access delivers all records that match the contents of the 'name' data field:
SELECT tab1.id, tab1.name, tab2.id, tab2.name
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name)
As one can see, this SQL query requires a column with an ID clearly identifying each record to ensure that a record is not compared with itself. Furthermore, this ID is required to ensure that the record with the biggest ID only appears in the column ‘tab1.id’, but not in the column ‘tab2.id’. This ensures that the record with the biggest ID from a duplicates group is not deleted. The IDs of the records that are to be deleted are written in column 'tab2.id'. This is how it looks when the results are integrated into a DELETE command for Access:
DELETE FROM tablename
WHERE id IN
(SELECT tab2.id
FROM tablename tab1, tablename tab2
WHERE tab1.name=tab2.name
AND tab1.id<>tab2.id
AND tab1.id=(SELECT MAX(id) FROM tablename tab
WHERE tab.name=tab1.name))
Of course, this SQL command can be easily extended to include other data fields in addition to the contents of the 'name' data field, for example, the data fields that contain the postal address.
You can read more about the options SQL provides to search for fuzzy duplicates in the article ‘Fuzzy matching with SQL'. But only specialised tools that include an error-tolerant (fuzzy) matching algorithm can provide a satisfactory solution to this problem, such as DataQualityTools.