

To do so, follow the steps below:
- If you have not already done so, download BatchDeduplicator free of charge here. Install the program and request a trial activation. Then you can work with the program for one whole week without any restrictions.
- First, you have to create a new project and provide all the required information for the duplicate detection. To do so, open the project administration.
- After clicking on 'Create new project', ...

... a dialogue appears where you must start by entering a name for the new project.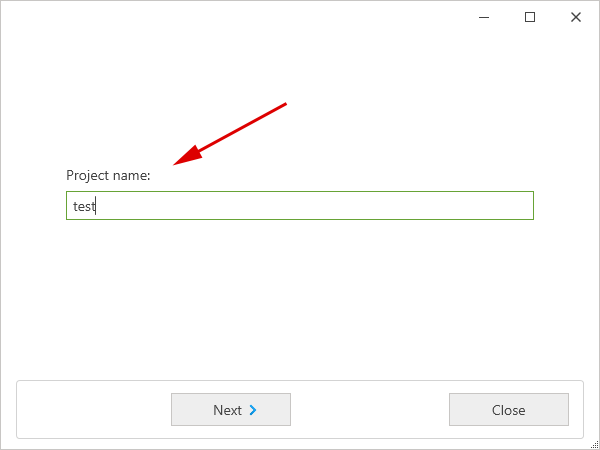
After clicking on 'Next', the project type can be selected. The choices include 'Matching within a table', 'Matching between two tables', 'Multiple deduplication' and the 'Faulty addresses list'. Let’s select 'Matching within a table'.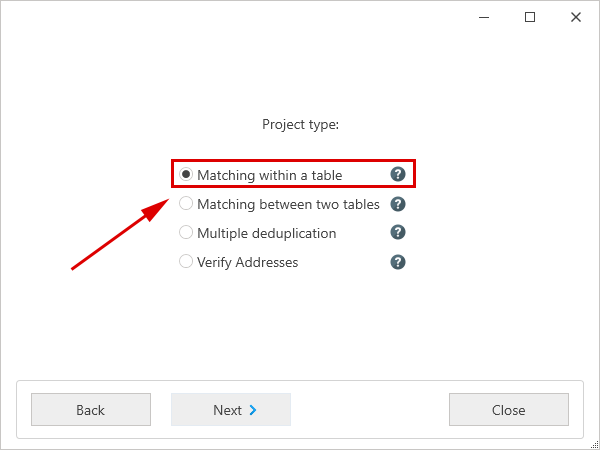
After another click on 'Next', you have to select the criteria to be used for the duplicate detection with the matching functions, for example, the postal address or the telephone number. Let’s select the postal address for the matching criterion.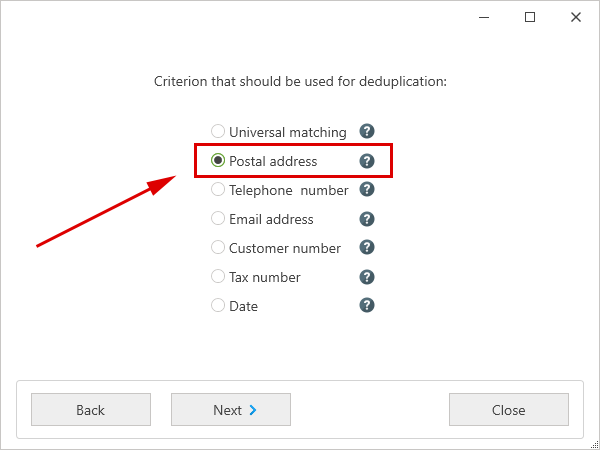
After one last click on 'Next' and then on 'Finish', the program automatically opens the 'Edit project' dialogue. - There, you can open the file with the data to be processed by clicking on 'Open file'.

With database servers (MS SQL Server, MySQL, Oracle or PostgreSQL), we have to select the corresponding database server instead, in the 'Format / Access to' selection list. After that, we enter the name of the database server. After clicking on the 'Connect to server' button, the access data have to be entered. Finally, the desired database containing the table can be selected in the corresponding selection lists. - Afterwards, the program has to be told in which columns it can find what information in the table, i.e., which column contains the street or name of the city. To do so, you have to select each data field from the table from the selection list with the column headings that fits best with the designation on the left.

The program automatically carries out a default field assignment using the column headings. Since we want to search for duplicates based on the postal address, we also have to indicate the respective columns from the table to be processed that contain the information for all of the components of the postal address. The results of the field assignment can be verified by using 'Verify field assignment’, which can be found on the right half of the screen. - With the 'Next' button, we come to the dialogue where the actual function can be configured. Here, the most important step is to set the threshold for the maximum allowed discrepancy between two addresses.

Furthermore, individual components of the postal address can be excluded from the comparison. In doing so, a column from the table to be processed has to be indicated, during the field assignment in the previous step, for each component of the postal address that should be included in the comparison. - Finally, you have to tell the program how it should transform the matching results, i.e., if it should delete duplicate records directly in the source file or only flag them. A click on the 'Next' button takes you to the overview with the available transformation functions. Let’s select 'Standard deletion log' and the 'Results file'.
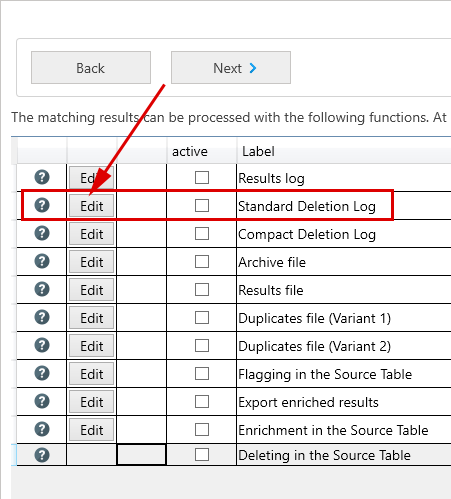
You have to enter a file name for each. The results file will contain the cleansed data. - Good, so now there should be a green checkmark in front of our project in the overview with the available projects. Thus, the project is complete and ready to be executed. You can start the project by clicking on 'Process project'. Then it will be executed immediately.
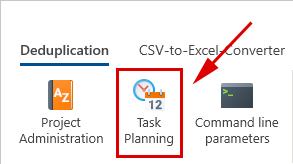
- In our case, however, the project should not be executed immediately, but rather automatically every Monday at 8 pm. To configure the project accordingly, click on 'Close' to close the project administration and then select the function 'Task planning'.
In the line with our project, click on the 'configure' button.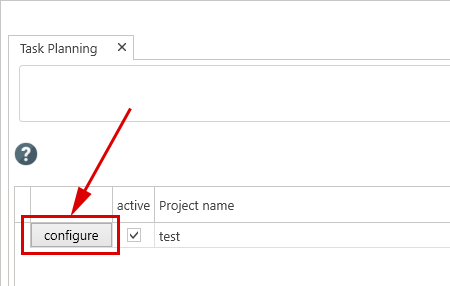
In the dialogue that then appears, select 'Execute weekly' and add 'Execute every week on Monday at 8 pm'.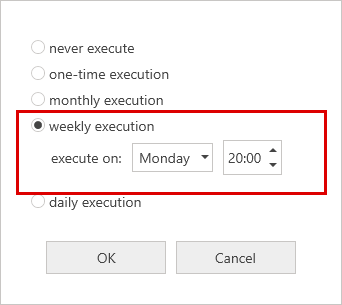
Before you close the 'Task planning' function, the program might ask if BatchDeduplicator should be started with the starting of the operating system, since only then can the planned projects be started and processed automatically.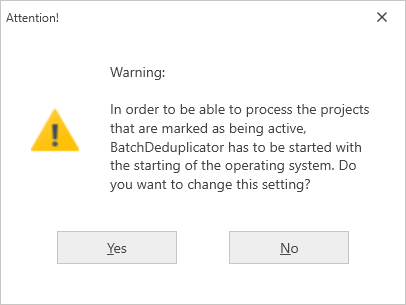
When BatchDeduplicator processes projects automatically, it creates an execution log that contains all the information about what was done at which time with the project. This includes a deletion log and a backup, which is created automatically when records were deleted or modified. You can open the execution log by using the corresponding button in the main window.
It is, of course, convenient to be able to run a project unattended. However, if a problem arises, you naturally want to be informed about it. You can read about how to set up a notification email in BatchDeduplicator in the article 'Setting up a notification email'.
You can read about how to use DedupeWizard to search for duplicates within an address list in the article 'Remove Duplicates in Excel'. You can read about how to use DataQualityTools to search for duplicates between two tables in the article 'Find Duplicates between two Tables in Access'.